Обученная на нескольких миллионах видео модель Speech2Face основывается на трех основных параметрах: поле, расе и возрасте.
 Создатели алгоритма утверждают, что по голосу человека легко можно определить пол, чуть сложнее — возраст, а наличие акцента дает общее представление о национальности. В результате этого можно примерно представить, как выглядит человек, однако, стоит учесть, что это представление не будет достаточно точным.
Создатели алгоритма утверждают, что по голосу человека легко можно определить пол, чуть сложнее — возраст, а наличие акцента дает общее представление о национальности. В результате этого можно примерно представить, как выглядит человек, однако, стоит учесть, что это представление не будет достаточно точным.
Для обучения нейросети ученые Массачусетского технологического института использовали базу данных, состоящую из более миллиона коротких видео более ста тысяч разных людей, каждое из которых разделено на аудио- и видеодорожку.
Архитектура натренированной нейросети устроена следующим образом. Сначала предварительно натренированный алгоритм использует особенности лица человека из кадра на видео для создания изображения лица человека в анфас с нейтральным выражением лица. Другая часть алгоритма воссоздает из аудиодорожки использованного видео спектрограмму речи и дает на выход примерное изображение лица человека, который разговаривает на видео.
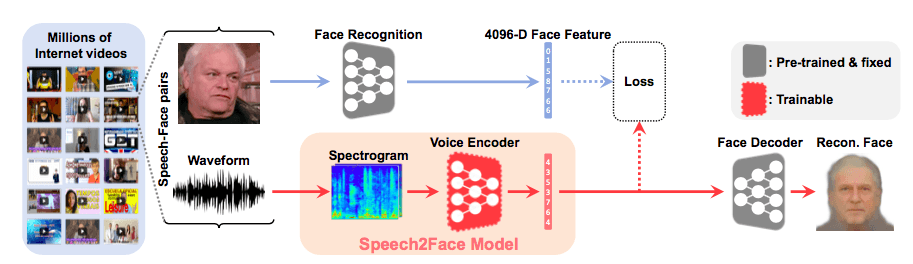
Степень точности созданного алгоритма ученые оценили по трем демографическим показателям: полу, примерному возрасту и расе. Несмотря на то, что воссоздание изображений некоторых людей было достаточно успешным, объективная оценка выявила несовершенство разработанной модели. В частности, нейросеть редко может определить возраст с точностью до десяти лет, а также лучше всего «рисует» людей с европеоидной и азиатской внешностью. Впрочем, последнее разработчики объяснили неравномерной выборкой рас в использованных видео.
Сообщает N+1